RAG学习
RAG
RAG简述
1、RAG的作用:在使用通用模型的时候,可能会存在一些专业领域的知识盲区,导致AI在上下文的时候得不到参考材料,从而出现胡说八道的幻觉。RAG为了解决这种情况,让模型通过内部知识记忆与RAG提供来自外部知识库的非参数化知识结合,使得模型在生成文本前,能通过检索从外部知识库中获取到相关信息,并将这些参考资料融入到生成过程中达到更准确的效果。
2、RAG通过以下的阶段来实现类似于检索结合内部与外部知识:
- 通过嵌入模型(
Embedding Model)将外部知识库编码为索引存到向量数据库中 - 当用户发起查询时,用同样的嵌入模型将问题向量化,并根据相似度从向量数据中锁定跟问题有关的文档片段。
- 得到检索阶段送来的相关文档片段和原始问题后,遵循预设的
Prompt指令,将将上下文与问题有效整合引导大模型进行准确的响应。
3、RAG的优势:
在使用模型的时候,当模型的响应不满足要求的时候,一般会采用一些方案来让模型的响应更符合自己的需求,一般是如下三种
- Prompt工程:精心设计提示词来引导模型,适合模型已有相关知识的场景。
- RAG:当模型缺乏特定的专业知识无法回答,使用RAG为其提供相关非参数化知识的上下文信息。
- 模型微调:当需要改变模型的行为和风格,微调才是最终的选择,能将复杂的指令蒸馏进模型的权重中。
4、RAG的关键优势:
- 准确度提升:相比较于Prompt工程,
RAG能解决了模型预训练知识的限制,补充了模型的知识盲区,且RAG生成的内容在提供的外部知识库中都是可以找到的,具备可信度。 - 时效性:模型在训练完成后会存在知识滞后的问题,RAG通过引入外部知识库能够进行动态更新,使得模型知识能够得到实时知识的补充。
- 性比价:相比于微调,
RAG外部知识库的强力辅助不需要重新对模型进行训练,避免了算力成本,并且在处理特定领域问题时,可以通过RAG的补充,使用参数量更小的基础模型进行推理,降低了推理的成本。
如何快速构建?
- 数据准备:将外部知识库如
PDF、Word、Markdown等多源头的数据变成标准化的数据,采用合理的分块策略进行切割。 - 索引构建:将切分好的文本通过嵌入模型转化为向量,并存入数据库。
- 检索优化:采用混合检索(向量+关键词)等方式来提升召回率,并引入重排序模型对检索结果进行二次精选。
- Prompt生成:设计清晰的
Prompt模板,引导 LLM 基于检索到的上下文回答用户问题。
数据加载
RAG系统中,数据加载是通过文档加载器将各种不同格式的文档转换成程序可处理的结构化数据,一般有各种不同的文档加载器,一般文档加载器需要将内容提取成纯文本,同时在解析过程中同时抽取文档来源、页码、作者等关键信息作为元数据,再将文本和元数据整理成统一的数据结构,方便后续切割入库。
主流的文档加载器;
| 加载器名称 | 处理格式 | 特点 |
|---|---|---|
| TextLoader | 基础文本文件加载 | 纯文本处理 |
| DirectoryLoader | 批量目录文件处理 | 混合格式文档 |
| Unstructured | 多格式文档解析 | PDF、Word、HTML等 |
| CSVLoader | CSV文档解析 | .csv |
| WebBaseLoader | 网页 URL | 网页内容解析 |
| FireCrawlLoader | 网页内容抓取 | 实时网页内容抓取 |
| LlamaParse | 深度PDF结构解析 | |
| Docx2txtLoader | .docx | doc文档解析 |
| JSONLoader | .json | JSON解析器 |
以Unstructured为例,能识别的文档元素如下:
| 元素类型 | 定义 |
|---|---|
| Title | 具有标题特征的文本 |
| Paragraph | 连续、无列表 / 标题特征的正文文本 |
| UncategorizedText | 未分类的自由文本 |
| ListItem | 有序 / 无序列表的条目 |
| Table | 行列结构化的表格内容 |
| NarrativeText | 兜底文本类型:无法归为标题 / 段落 / 列表的零散文本 |
| Header | 页面顶部的重复文本 |
| Footer | 页面底部的重复文本 |
| PageBreak | 标识文档的分页位置 |
| SectionHeader | 比Title更细分的章节头部文本 |
| Footnote | 页面底部针对特定内容的注释 |
| Image | 文档中的图片元素 |
| Audio | 文档中的音频嵌入对象 |
| EmbeddedFile | 文档中嵌入的附属文件 |
| Code | 带语法特征的代码片段 |
| FigureCaption | 图片 / 图表下方的说明文本 |
| Address/Phone/EmailAddress | 邮箱、地址 |
| PageBreak | 页面分隔符 |
| PageNumber | 页码 |
示例代码:
from unstructured.partition.auto import partition
from collections import Counter
# -------------------------- 配置参数 --------------------------
pdf_path = "TEST.pdf" # 你的PDF路径
# 中文解析关键参数:简体中文+英文(适配中文PDF/OCR)
OCR_LANGUAGES = "chi_sim+eng"
# 文本截断长度(避免长文本刷屏,可根据需要调整)
TEXT_TRUNCATE_LEN = 300
# 编码格式(解决中文乱码)
ENCODING = "utf-8"
# -------------------------- 核心解析逻辑 --------------------------
def parse_pdf_with_unstructured(pdf_path):
try:
# 3. 解析PDF(补充中文适配参数)
elements = partition(
filename=pdf_path,
content_type="application/pdf",
)
# 4. 过滤空元素(避免统计无效内容)
elements = [elem for elem in elements if elem.text.strip()]
return elements
except Exception as e:
print(f"❌ PDF解析失败:{str(e)}")
return None
# -------------------------- 执行解析并输出结果 --------------------------
if __name__ == "__main__":
# 解析PDF
elements = parse_pdf_with_unstructured(pdf_path)
# 1. 精准统计(改用element.text,避免元数据干扰)
total_elements = len(elements)
total_chars = sum(len(elem.text.strip()) for elem in elements)
print(f"✅ 解析完成: {total_elements} 个有效元素, 总字符数: {total_chars}")
# 2. 统计元素类型(按数量降序排列)
type_counter = Counter(e.category for e in elements)
print(f"\n📊 元素类型分布: {dict(type_counter.most_common())}")
# 3. 友好显示所有元素(截断长文本)
print("\n📝 所有元素详情:")
print("-" * 80)
for i, element in enumerate(elements, 1):
# 截断过长的文本,保留关键内容
display_text = element.text.strip()
if len(display_text) > TEXT_TRUNCATE_LEN:
display_text = display_text[:TEXT_TRUNCATE_LEN] + "..."
print(f"Element {i} ({element.category}):")
print(element)
print(f"内容: {display_text}")
print("-" * 80)文本分块
1、文本分块是将数据加载出来的长篇文档,切分成小块且易处理的小文本块,由于嵌入模型有严格的输入长度(Token)限制,文本块的大小必须小于等于嵌入模型的上下文窗口,同时由于LLM同样有上下文窗口限制,与用户的问题和提示放入的时候,需要尽可能容纳的块要很相关,因此分块后的文本块的质量非常重要。
2、如何定义分出来的一个文本块是质量高的?
LLM就回答的过程中,当文本块很长,LLM会充满大量的上下文使得关键信息被稀释,从而导致型就很难从中提取出最关键的信息来形成答案。因此一个好的文本块主题是明确且一致的。
3、嵌入的过程中,文本内容是被压缩成向量的,因此信息损失是不可避免的,以Transformer编码器的压缩过程为例:
- 分词 (Tokenization): 将文本拆成模型的最小单元(Token)
- 向量化 (Vectorization): Transformer 为每个 token 生成一个高维向量表示(768/1024 个数字组成的数组)。
- 池化 (Pooling): 将所有 token 的向量压缩成一个单一的向量,这个向量代表了整个文本块的语义(平均池化、[CLS]位取向量等)。
以
RMIConnector为例
分词:[CLS]、R、M、I、C、o、n、n、e、c、t、o、r、[SEP]向量化:CLS 模拟成[0.12, -0.35, 0.28, 0.41, -0.19]类似的向量,预训练时代表整句语义
R模拟成[0.15, -0.32, 0.29, 0.38, -0.21]和 M/I 语义关联,向量数值接近。
池化:平均池化:第1维:(0.12+0.15+..+..)/n得到平均维
分块策略
固定分块:默认采用\n\n分割符,使用正则表达式将文本按段落进行分割,交给_merge_splits函数进行智能合并,按顺序添加片段,并实时计算累计长度,当超过了chunk_size,触发生成一个块。生成块后,从头部移除片段,保留尾部chunk_overlap,作为下一个块的开始,实现重叠。
class CharacterTextSplitter(TextSplitter):
"""Splitting text that looks at characters."""
def __init__(
self,
separator: str = "\n\n",
is_separator_regex: bool = False,
**kwargs: Any,
) -> None:
"""Create a new TextSplitter."""
super().__init__(**kwargs)
self._separator = separator
self._is_separator_regex = is_separator_regex
def split_text(self, text: str) -> list[str]:
sep_pattern = (
self._separator if self._is_separator_regex else re.escape(self._separator)
)
splits = _split_text_with_regex(
text, sep_pattern, keep_separator=self._keep_separator
)
lookaround_prefixes = ("(?=", "(?<!", "(?<=", "(?!")
is_lookaround = self._is_separator_regex and any(
self._separator.startswith(p) for p in lookaround_prefixes
)
merge_sep = ""
if not (self._keep_separator or is_lookaround):
merge_sep = self._separator
return self._merge_splits(splits, merge_sep)递归分块:
遍历分隔符列表,找到文本中第一个存在的分隔符作为当前分割依据,并记录剩余更低优先级分隔符。
用转义后选定的分隔符分割文本,得到初始的分割结果
遍历初始分割结果 splits,逐个检查片段大小是否符合 chunk_size:
-
小片段:暂存到
good_splits,后续合并成完整块。 -
超大片段:先处理已暂存的小片段(合并后加入最终结果),再判断是否能递归分割:
-
无剩余分隔符:直接保留超大片段。
-
有剩余分隔符:用更低优先级分隔符递归调用
_split_text** 分割该片段,结果加入最终列表。
遍历完所有初始片段后,若
good_splits还有未处理的小片段,合并后加入最终结果。 -
def _split_text(self, text: str, separators: list[str]) -> list[str]:
final_chunks = []
separator = separators[-1]
new_separators = []
for i, _s in enumerate(separators):
separator_ = _s if self._is_separator_regex else re.escape(_s)
if not _s:
separator = _s
break
if re.search(separator_, text):
separator = _s
new_separators = separators[i + 1 :]
break
separator_ = separator if self._is_separator_regex else re.escape(separator)
splits = _split_text_with_regex(
text, separator_, keep_separator=self._keep_separator
)
good_splits = []
separator_ = "" if self._keep_separator else separator
for s in splits:
if self._length_function(s) < self._chunk_size:
good_splits.append(s)
else:
if good_splits:
merged_text = self._merge_splits(good_splits, separator_)
final_chunks.extend(merged_text)
good_splits = []
if not new_separators:
final_chunks.append(s)
else:
other_info = self._split_text(s, new_separators)
final_chunks.extend(other_info)
if good_splits:
merged_text = self._merge_splits(good_splits, separator_)
final_chunks.extend(merged_text)
return final_chunks语义分块:SentenceTransformersTextSplitter 是语义驱动的文本分割器,会通过模型生成每个单元的语义嵌入向量,计算相邻单元的语义相似度,最终将语义相近的单元合并成符合 chunk_size 要求的块,大致流程如下:
-
默认按自然语言的句子分隔符拆分,得到一个个独立的小句子/分句作为语义单元。
-
对于最小的语义单元,调用
SentenceTransformers模型生成嵌入向量,向量在高维空间中的距离越近;语义差异越小。 -
计算每两个相邻语义单元的
余弦相似度(或欧氏距离):相似度越接近 1,语义越相关;越接近 0,语义越无关,将相似度转换成将相似度转换为差异度,说明两个单元的语义关联越弱,是最优分割点。 -
合并语义单元,持续向列表中添加下一个相邻单元,同时计算合并后的总长度:
-
若总长度 未超过
chunk_size:继续添加下一个单元。 -
若总长度 即将超过
chunk_size:检查当前列表最后一个单元与下一个单元的差异度,若差异度高,直接分割,将待合并列表中的单元拼接成一个块,加入最终结果。若差异度低,会临时突破 chunk_size,把这个相关单元也加入,再分割。
-
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from langchain_classic.text_splitter import SentenceTransformersTokenTextSplitter
from langchain_community.document_loaders import TextLoader
semantic_splitter = SentenceTransformersTokenTextSplitter(
chunk_size=20,
chunk_overlap=5,
model_name="paraphrase-multilingual-MiniLM-L12-v2" # 直接用模型名,从镜像下载
)
loader = TextLoader("test.txt")
docs = loader.load()
chunks = semantic_splitter.split_text(str(docs))
print("分割结果:")
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}: {chunk}")文档结构分块:langchain_classic提供了针对多项结构清晰文档的分块器,如HTMLHeaderTextSplitter、MarkdownHeaderTextSplitter等,如MarkDown大致原理如下:
- 定义标题层级规则:提供一个标题层级的映射关系,告诉分块器那些是几级标题
- 提取内容:分割器逐行扫描 Markdown 文本,通过正则/字符串匹配识别所有符合规则的标题行,同时记录标题的层级、在文档中的位置
- 生成文本块:每个块包含
元数据(记录当前块的完整标题层级)以及内容(标题文字 + 其管辖的所有内容) - 如果某个标题下的内容超过你设定的
chunk_size,分割器会自动调用RecursiveCharacterTextSplitter对内容进行二次拆分,保证块大小符合要求,同时保留标题元数据。
for sep, name in self.headers_to_split_on:
is_standard_header = stripped_line.startswith(sep) and (
len(stripped_line) == len(sep) or stripped_line[len(sep)] == " "
)
is_custom_header = self._is_custom_header(stripped_line, sep)
if is_standard_header or is_custom_header:
if name is not None:
if sep in self.custom_header_patterns:
current_header_level = self.custom_header_patterns[sep]
else:
current_header_level = sep.count("#")
while (
header_stack
and header_stack[-1]["level"] >= current_header_level
):
popped_header = header_stack.pop()
if popped_header["name"] in initial_metadata:
initial_metadata.pop(popped_header["name"])
if is_custom_header:
header_text = stripped_line[len(sep) : -len(sep)].strip()
else:
header_text = stripped_line[len(sep) :].strip()
header: HeaderType = {
"level": current_header_level,
"name": name,
"data": header_text,
}
header_stack.append(header)
if current_content:
lines_with_metadata.append(
{
"content": "\n".join(current_content),
"metadata": current_metadata.copy(),
}
)
current_content.clear()
if not self.strip_headers:
current_content.append(stripped_line)
break向量嵌入
1、Embedding(向量嵌入) 将所有的数据对象转换成低维、连续的数值向量技术,相当于赋予一个独一无二的坐标。当语义相似的对象,它对应向量在多维空间中的距离会较近,一般有以下方式度量距离:
- 余弦相似度 (Cosine Similarity) :计算两个向量夹角的余弦值。值越接近 1,代表方向越一致,语义越相似。这是最常用的度量方式。
- 点积 (Dot Product) :计算两个向量的乘积和。在向量归一化后,点积等价于余弦相似度。
- 欧氏距离 (Euclidean Distance) :计算两个向量在空间中的直线距离。距离越小,语义越相似
2、Transformer自注意力机制的诞生,使BERT 模型通过堆叠多个 Transformer 的编码器提出了预训练语言模型,实现了真正深度双向上下文理解。
BERT 的输入由三部分组成,通过嵌入层 (Embedding) 融合:
- Token Embeddings:词 / 子词的基础向量表示(使用 WordPiece 分词)
- Segment Embeddings:区分两个句子(如问答任务中的问题和上下文)
- Position Embeddings:编码词在句子中的位置信息
特殊标记:
- [CLS]:放在句子开头,用于分类任务的聚合表示
- [SEP]:分隔两个句子或标记句子结束
- [MASK]:用于预训练的掩码语言模型任务
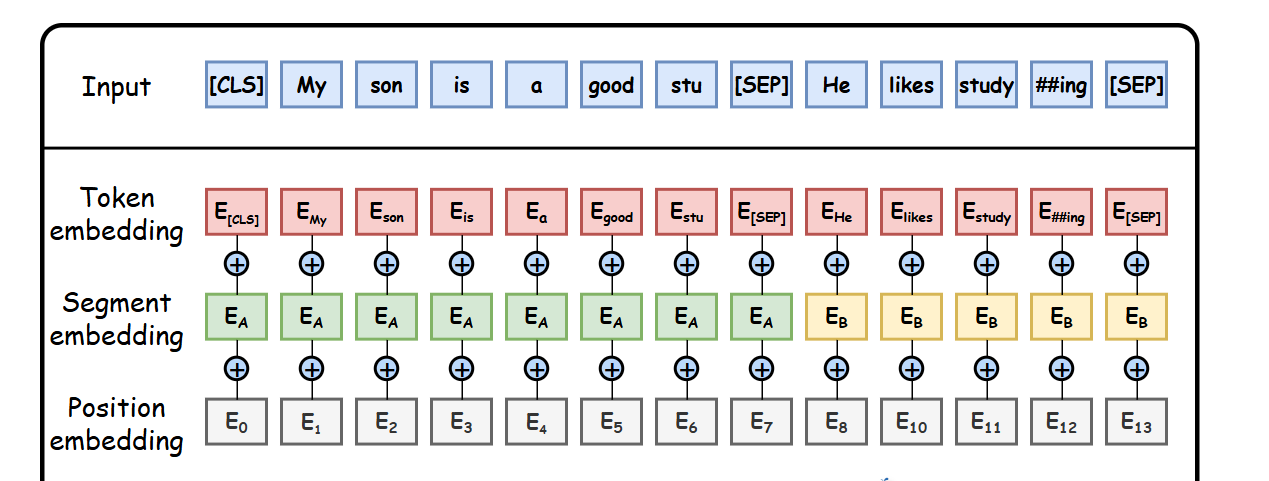
3、预训练模型主要的训练任务:
掩码语言模型 (MLM)
- 随机掩盖 15% 的输入词(用 [MASK] 标记)
- 训练模型预测被掩盖的原始词
- 确保模型学习上下文依赖性,而非简单记忆
下一句预测 (NSP)
- 输入一对句子 (A,B)
- 50% 概率 B 是 A 的真实下一句,50% 概率是随机句子
- 训练模型判断 B 是否为 A 的下一句
- 帮助模型学习句子间的逻辑关系和连贯性

现代模型还会引入度量学习和三元组对比学习进行针对性的训练:
| 度量学习 | 对比学习 |
|---|---|
| 文本对 | 三元组:(Anchor, Positive, Negative) |
| 正例对拉近、负例对拉远 | Anchor 和 Positive 是相关的,Anchor 和 Negative 是不相关的 |
| 全局的相对距离分布 | 局部的两两对比关系 |
| 较宽松:只保证正例整体比负例近 | 更严格:同一锚点下,正例必须显著比负 |
| 简单匹配、粗粒度相似度排序精细检索 | 聚类、小样本分类、句向量编码 |
大语言模型的综合性能:https://huggingface.co/spaces/mteb/leaderboard
多模态嵌入
多模态嵌入:由于现实世界有图像、音频、视频等各种数据信息,向量嵌入仅能满足文本,多模态嵌入将不同类型的数据(如图像和文本)映射到同一个共享的向量空间。
如OpenAI 的 CLIP (Contrastive Language-Image Pre-training)核心结构:
- 图像编码器(如 ResNet、Vision Transformer,ViT):只负责把图片编码成一个固定维度的向量 I
- 文本编码器(如 Transformer、类 BERT 结构):只负责把文本编码成一个固定维度的向量 T
对齐语义:训练目标不是让图像和文本特征长得一样,而是语义等价的图文,在共享向量空间里挨得近;语义无关的,离得远
对比学习:正例拉近,负例推远,只是 CLIP 把它用在了「图像 - 文本」两种模态之间。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import torch
from PIL import Image
import numpy as np
from transformers import CLIPProcessor, CLIPModel, CLIPConfig
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "./models/damo/multi-modal_clip-vit-base-patch16_zh"
model_name = "openai/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_name).to(device)
processor = CLIPProcessor.from_pretrained(model_name)
def compute_similarity(image_features, text_features):
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
similarity = (image_features @ text_features.T).squeeze()
return similarity.cpu().numpy()
image = Image.open("./img.png").convert("RGB")
test_texts = [
"a photo of a cat",
"一只可爱的小猫",
"a photo of a dog",
"a red car",
"a black and white cat",
"an animal with fur",
"a person riding a bicycle",
"a cat sitting on a couch",
"orange cat"
]
print("\n正在处理图像和文本...")
inputs = processor(text=test_texts, images=image, return_tensors="pt", padding=True).to(device)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
similarities = compute_similarity(image_features, text_features)
sorted_indices = np.argsort(similarities)[::-1]
for rank, idx in enumerate(sorted_indices, 1):
similarity_score = similarities[idx]
text = test_texts[idx]
if similarity_score > 0.25:
marker = "✓"
color_code = "\033[92m"
elif similarity_score > 0.15:
marker = "~"
color_code = "\033[93m"
else:
marker = "✗"
color_code = "\033[91m"
print(f"{rank:2d}. {marker} {color_code}相似度: {similarity_score:.4f}\033[0m")
print(f" 文本: {text}")
if rank < len(sorted_indices):
print()
print("\n" + "=" * 70)
print(f"最高相似度: {similarities[sorted_indices[0]]:.4f}")
print(f"最低相似度: {similarities[sorted_indices[-1]]:.4f}")
print(f"平均相似度: {np.mean(similarities):.4f}")
向量数据库
| 维度 | 向量数据库 | 传统数据库 (RDBMS) |
|---|---|---|
| 核心数据类型 | 高维向量 (Embeddings) | 结构化数据 (文本、数字、日期) |
| 查询方式 | 相似性搜索 (ANN) | 精确匹配 |
| 索引机制 | HNSW, IVF, LSH 等 ANN 索引 | B-Tree, Hash Index |
| 数据规模 | 轻松应对千亿级向量 | 通常在千万到亿级行数据,更大规模需复杂分库分表 |
| 性能特点 | 高维数据检索性能极高,计算密集型 | 结构化数据查询快,高维数据查询性能呈指数级下降 |
| 一致性 | 通常为最终一致性 | 强一致性 (ACID 事务) |
向量数据库索引机制:
1、LSH(Locality Sensitive Hashing,局部敏感哈希):让「相似的向量更大概率映射到同一个哈希桶」,检索时只需在同一个桶内计算相似度,避免全量遍历。
- 用多个独立的哈希函数对向量进行哈希,每个哈希函数都满足 “相似向量哈希冲突概率更高” 的局部敏感特性。
- 把向量分配到对应的哈希桶中,检索时先通过哈希函数找到查询向量所在的桶,再在桶内做精确相似度计算。
- 为了提高召回率,通常会用多个哈希函数生成多个哈希表,最终取所有哈希表结果的交集 / 并集
2、IVF(Inverted File,倒排文件):先把向量空间聚类成多个 “中心”,再把向量分配到最近的中心对应的桶里。检索时先定位到查询向量的最近几个中心,只在这些中心的桶内做精确搜索
- 聚类建桶:用 K-means 等算法把所有向量聚成 nlist 个簇(中心),每个簇对应一个桶。
- 向量分配:把每个向量分配到距离最近的中心所在的桶。
- 检索流程:先计算查询向量与所有中心的相似度,找到最近的 k 个中心,然后只在这 k 个中心的桶内计算向量相似度,得到最终结果。
3、HNSW(Hierarchical Navigable Small World,分层可导航小世界图):构建多层图结构,检索时先在上层快速定位到大致区域,再逐层下探,最终找到最近邻。
- 多层图结构:底层是包含所有向量的稠密图,上层是底层图的稀疏采样。每一层的节点都是下层节点的子集,且边的数量更少。
- 小世界网络特性:图中任意两个节点之间只需通过少量边即可到达,保证了检索的高效性。
- 检索流程:从最上层开始,通过贪心算法找到距离查询向量最近的节点,然后逐层向下,在每层中优化候选节点,最终在底层得到精确的最近邻。
当前主流的向量数据库
| 产品名称 | 主要类型/模式 | 核心特点 | 典型适用场景 |
|---|---|---|---|
| Pinecone | 全托管云服务 | 开箱即用、自动扩缩容、零运维负担 | 快速原型验证、实时推荐系统、追求开发效率的场景 |
| Milvus | 开源,可自托管或云托管 | 专为海量向量设计、分布式架构、性能强悍、生态丰富 | 超大规模图像/视频检索、大规模推荐系统 |
| Weaviate | 开源/托管可选 | 原生支持混合搜索(向量+关键词)、模块化、GraphQL接口 | 知识图谱、复杂混合搜索、快速构建AI应用 |
| Qdrant | 开源,可自托管或云托管 | 用Rust编写、性能与资源效率高、支持丰富的数据过滤 | 实时推荐、广告系统、对性能有高要求的场景 |
| Chroma | 轻量级嵌入式/开源 | 极其简单、API友好、与LLM应用(如RAG)集成紧密 | 本地开发测试、快速原型、中小型RAG应用 |
| 腾讯云向量数据库 (VDB) | 全托管云服务 | 开箱即用、深度集成腾讯云生态及AI套件、宣称高性价比 | 大模型知识库、混合检索等腾讯云生态内场景 |
| Vespa.ai | 开源,可自托管 | 支持复杂排序和过滤的低延迟计算平台,在GigaOm 2025年报告中被评为领导者 | 需要低延迟、复杂自定义处理的大规模数据计算 |
| FAISS | 开源 | 提供多种高效的近似最近邻搜索算法,追求极致的搜索速度和资源效率 | 作为高性能搜索引擎,或用于对延迟极度敏感、数据规模固定的研究与原型开发。 |
在本地可以通过FAISS+Langchain构建一个强大的本地向量存储方案,非常适合快速原型设计和中小型应用
import os
import torch
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HOME'] = './models/huggingface'
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_classic.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
device = "cuda" if torch.cuda.is_available() else "cpu"
print("正在加载嵌入模型...")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': device}
)
documents = [
Document(page_content="Python是一种高级编程语言,由Guido van Rossum于1991年首次发布。它具有简洁明了的语法,支持多种编程范式,包括面向对象、命令式、函数式和过程式编程。"),
Document(page_content="LangChain是一个用于开发由语言模型驱动的应用程序的框架。它提供了模块化的组件,可以轻松地构建复杂的AI应用,包括聊天机器人、问答系统等。"),
Document(page_content="FAISS(Facebook AI Similarity Search)是Meta开发的一个用于高效相似性搜索和密集向量聚类的库。它特别适合处理大规模向量数据,支持GPU加速。"),
Document(page_content="向量数据库是一种专门用于存储和检索向量数据的数据库。它们通过计算向量之间的相似度来查找最相关的数据,广泛应用于推荐系统、图像检索和语义搜索等领域。"),
Document(page_content="RAG(Retrieval-Augmented Generation)是一种结合检索和生成的AI技术。它先从知识库中检索相关信息,然后基于这些信息生成答案,可以提高回答的准确性和可靠性。"),
Document(page_content="Transformer是一种基于自注意力机制的深度学习模型架构,由Google在2017年提出。它是现代大语言模型(如GPT、BERT)的基础,能够有效地处理序列数据。"),
Document(page_content="微调是指在预训练模型的基础上,使用特定领域的数据进行进一步训练,使模型适应特定任务的过程。相比于从头训练,微调需要的数据量和计算资源都更少。"),
Document(page_content="提示词工程是指设计和优化输入给语言模型的提示词,以获得更好的输出结果的技术。好的提示词可以显著提高模型的性能和准确性。"),
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
length_function=len,
)
print("\n正在分割文档...")
texts = text_splitter.split_documents(documents)
print(f"分割后得到 {len(texts)} 个文本块")
print("\n正在创建FAISS向量数据库...")
vectorstore = FAISS.from_documents(texts, embeddings)
print("向量数据库创建完成!")
print("\n" + "=" * 70)
print("相似度搜索测试")
print("=" * 70)
queries = [
"什么是向量数据库?",
"Python有什么特点?",
"如何提高AI模型的准确性?",
"Transformer是什么?",
]
for query in queries:
print(f"\n查询: {query}")
print("-" * 70)
results = vectorstore.similarity_search_with_score(query, k=3)
for i, (doc, score) in enumerate(results, 1):
print(f"\n结果 {i} (相似度: {score:.4f}):")
print(f"内容: {doc.page_content}")
print("=" * 70)
print("保存向量数据库")
print("=" * 70)
vectorstore.save_local("./faiss_index")
print("向量数据库已保存到 ./faiss_index 目录")
print("\n" + "=" * 70)
print("加载向量数据库并测试")
print("=" * 70)
loaded_vectorstore = FAISS.load_local("./faiss_index", embeddings, allow_dangerous_deserialization=True)
print("向量数据库加载成功!")
test_query = "什么是RAG技术?"
print(f"\n测试查询: {test_query}")
print("-" * 70)
results = loaded_vectorstore.similarity_search_with_score(test_query, k=2)
for i, (doc, score) in enumerate(results, 1):
print(f"\n结果 {i} (相似度: {score:.4f}):")
print(f"内容: {doc.page_content}")
print("\n" + "=" * 70)
print("测试完成!")
print("=" * 70)
Milvus
环境安装
wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.yml样例:
import torch
from PIL import Image
import numpy as np
from typing import List, Dict, Union, Optional
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
from transformers import CLIPProcessor, CLIPModel
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HOME'] = './models/huggingface'
class MultiModalRetriever:
def __init__(
self,
model_name: str = "openai/clip-vit-base-patch32",
milvus_host: str = "192.168.78.128",
milvus_port: int = 19530,
collection_name: str = "multimodal_search",
device: Optional[str] = None,
recreate_collection: bool = False,
):
self.device = device if device else ("cuda" if torch.cuda.is_available() else "cpu")
self.model_name = model_name
self.milvus_host = milvus_host
self.milvus_port = milvus_port
self.collection_name = collection_name
self.collection = None
self.recreate_collection = recreate_collection
print(f"使用设备: {self.device}")
self._load_model()
self._connect_milvus()
self._create_collection()
def _load_model(self):
print(f"正在加载模型: {self.model_name}")
try:
self.model = CLIPModel.from_pretrained(self.model_name).to(self.device)
self.model.eval()
self.processor = CLIPProcessor.from_pretrained(self.model_name)
print("模型加载成功!")
except Exception as e:
print(f"模型加载失败: {e}")
raise
def _connect_milvus(self):
print(f"正在连接 Milvus: {self.milvus_host}:{self.milvus_port}")
try:
connections.connect(
alias="default",
host=self.milvus_host,
port=self.milvus_port
)
print("Milvus 连接成功!")
except Exception as e:
print(f"Milvus 连接失败: {e}")
raise
def _create_collection(self):
if utility.has_collection(self.collection_name):
if self.recreate_collection:
print(f"集合 {self.collection_name} 已存在,正在删除并重新创建...")
utility.drop_collection(self.collection_name)
else:
print(f"集合 {self.collection_name} 已存在,正在加载...")
self.collection = Collection(self.collection_name)
self.collection.load()
print("集合加载成功!")
return
print(f"正在创建集合: {self.collection_name}")
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=100),
FieldSchema(name="type", dtype=DataType.VARCHAR, max_length=10),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=512),
]
schema = CollectionSchema(
fields=fields,
description="多模态检索集合"
)
self.collection = Collection(
name=self.collection_name,
schema=schema
)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "IP",
"params": {"nlist": 128}
}
self.collection.create_index(
field_name="embedding",
index_params=index_params
)
self.collection.load()
print("集合创建并加载成功!")
def encode_text(self, texts: List[str]) -> np.ndarray:
with torch.no_grad():
inputs = self.processor(
text=texts,
return_tensors="pt",
padding=True,
truncation=True
).to(self.device)
text_features = self.model.get_text_features(**inputs)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
embeddings = text_features.cpu().numpy()
return embeddings
def encode_image(self, images: List[Union[str, Image.Image]]) -> np.ndarray:
processed_images = []
for img in images:
if isinstance(img, str):
img = Image.open(img).convert("RGB")
processed_images.append(img)
with torch.no_grad():
inputs = self.processor(
images=processed_images,
return_tensors="pt"
).to(self.device)
image_features = self.model.get_image_features(**inputs)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
embeddings = image_features.cpu().numpy()
return embeddings
def insert_texts(
self,
texts: List[str],
ids: Optional[List[str]] = None
) -> int:
if ids is None:
ids = [f"text_{i}" for i in range(len(texts))]
embeddings = self.encode_text(texts)
data = [
ids,
["text"] * len(texts),
texts,
embeddings.tolist()
]
insert_result = self.collection.insert(data)
self.collection.flush()
print(f"成功插入 {len(texts)} 条文本数据")
return insert_result.insert_count
def insert_images(
self,
image_paths: List[str],
ids: Optional[List[str]] = None,
descriptions: Optional[List[str]] = None
) -> int:
if ids is None:
ids = [f"image_{i}" for i in range(len(image_paths))]
if descriptions is None:
descriptions = image_paths
embeddings = self.encode_image(image_paths)
data = [
ids,
["image"] * len(image_paths),
descriptions,
embeddings.tolist()
]
insert_result = self.collection.insert(data)
self.collection.flush()
print(f"成功插入 {len(image_paths)} 条图像数据")
return insert_result.insert_count
def search(
self,
query: Union[str, List[str], Image.Image, List[Image.Image]],
top_k: int = 10,
search_type: Optional[str] = None
) -> List[Dict]:
if isinstance(query, str):
query_embeddings = self.encode_text([query])
query_type = "text"
elif isinstance(query, Image.Image):
query_embeddings = self.encode_image([query])
query_type = "image"
elif isinstance(query, list) and len(query) > 0:
if isinstance(query[0], str):
query_embeddings = self.encode_text(query)
query_type = "text"
else:
query_embeddings = self.encode_image(query)
query_type = "image"
else:
raise ValueError("不支持的查询类型")
search_params = {
"metric_type": "IP",
"params": {"nprobe": 10}
}
results = self.collection.search(
data=query_embeddings.tolist(),
anns_field="embedding",
param=search_params,
limit=top_k,
expr=None if search_type is None else f"type == '{search_type}'",
output_fields=["id", "type", "content"]
)
formatted_results = []
for idx, result in enumerate(results[0]):
result_dict = {
"id": result.id,
"score": result.score
}
if hasattr(result, "entity"):
result_dict["type"] = result.entity.get("type")
result_dict["content"] = result.entity.get("content")
elif hasattr(result, "get"):
result_dict["type"] = result.get("type")
result_dict["content"] = result.get("content")
else:
result_dict["type"] = None
result_dict["content"] = None
formatted_results.append(result_dict)
return formatted_results
def hybrid_search(
self,
text_query: str,
image_query: Union[str, Image.Image],
top_k: int = 10,
text_weight: float = 0.5,
image_weight: float = 0.5
) -> List[Dict]:
text_results = self.search(text_query, top_k=top_k)
image_results = self.search(image_query, top_k=top_k)
combined_scores = {}
for result in text_results:
if result["id"] not in combined_scores:
combined_scores[result["id"]] = {
"id": result["id"],
"type": result["type"],
"content": result["content"],
"score": result['score']
}
combined_scores[result["id"]]["score"] += result["score"] * text_weight
for result in image_results:
if result["id"] not in combined_scores:
combined_scores[result["id"]] = {
"id": result["id"],
"type": result["type"],
"content": result["content"],
"score": result['score']
}
combined_scores[result["id"]]["score"] += result["score"] * image_weight
sorted_results = sorted(
combined_scores.values(),
key=lambda x: x["score"],
reverse=True
)
return sorted_results[:top_k]
def delete_collection(self):
if utility.has_collection(self.collection_name):
utility.drop_collection(self.collection_name)
print(f"集合 {self.collection_name} 已删除")
def close(self):
connections.disconnect("default")
print("Milvus 连接已关闭")
def main():
print("=" * 70)
print("多模态检索引擎示例")
print("=" * 70)
retriever = MultiModalRetriever(
model_name="openai/clip-vit-base-patch32",
milvus_host="192.168.78.128",
milvus_port=19530,
collection_name="multimodal_search",
recreate_collection=True
)
print("\n" + "=" * 70)
print("插入示例文本数据")
print("=" * 70)
sample_texts = [
"一只可爱的橘色小猫坐在沙发上",
"红色跑车在高速公路上飞驰",
"一个人骑着自行车穿过公园",
"蓝天白云下的美丽风景",
"现代科技感的城市建筑",
"美味的披萨放在木桌上",
"森林中的小溪流水潺潺",
"夜晚的星空璀璨夺目",
]
image_paths = [
"./images/cat.png",
"./images/dog.png",
"./images/红色跑车.png",
]
retriever.insert_texts(sample_texts)
retriever.insert_images(image_paths)
print("\n" + "=" * 70)
print("文本检索测试")
print("=" * 70)
query_text = "猫"
print(f"\n查询: {query_text}")
print("-" * 70)
results = retriever.search(query_text, top_k=3)
for i, result in enumerate(results, 1):
print(f"\n结果 {i} (相似度: {result['score']:.4f}):")
print(f"类型: {result['type']}")
print(f"内容: {result['content']}")
retriever.insert_images(image_paths)
text_query = "橘色的猫"
image_query = Image.open("./images/img.png")
print(f"\n文本查询: {text_query}")
print(f"图像查询: img.png")
results = retriever.hybrid_search(
text_query=text_query,
image_query=image_query,
top_k=3,
text_weight=0,
image_weight=1
)
for i, result in enumerate(results, 1):
print(f"{i}. [{result['type']}] 综合相似度: {result['score']:.4f}")
print(f" {result['content']}\n")
retriever.close()
if __name__ == "__main__":
main()
检索
稀疏向量:向量的长度通常很高,但绝大多数元素的值都是 0,只有极少数位置是非零值,非零值的占比通常远低于 5%,使它的存储非常高效,但是无法捕捉语义关联,如BM25算法:
$$
BM25(D,Q) = Σ [ IDF(qi) × ((k1+1)×tf(qi,D))/(k1×((1−b)+b×|D|/avgdl) + tf(qi,D)) ]
$$
密集向量:嵌入向量(Embedding Vector),向量的长度(维度)通常较低几十、几百、几千维),且绝大多数(或全部)元素都是非零值,没有明显的稀疏性,能够捕抓语义关联。
比如一个8维数组,番茄在第3位、炒在第5位,蛋在第7位,权重分别是1.2、0.7、0.8
稀疏向量的坐标列表可表示为:
(8, [3, 5, 7], [1.2, 0.7, 0.8])密集向量则可能为,密集向量更有可能匹配到炒蛋类的菜:
[0.89, -0.12, 0.77, ..., -0.45]在现代的RAG中,很少单独使用 BM25(稀疏向量)或单独使用密集向量,而是采用「混合检索」:
- 先用 BM25 进行稀疏检索,召回和查询词「字面匹配」的相关文档,保证召回的准确性和可解释性。
- 再用密集向量进行语义检索,召回和查询「语义匹配」的相关文档,弥补 BM25 无法捕捉语义的短板(比如查询「苹果的电子产品」,BM25 可能只召回含「苹果」和「电子产品」的文档,而密集向量能召回含「iPhone」「Mac」的文档)。
- 最后对两种检索结果进行融合排序,得到更全面、更精准的最终结果。
如RFF算法:将多个独立排序结果(如不同检索模型、不同查询方式、不同数据源)合并为单一、更优的排序列表,完全基于排名位置而非原始分数,彻底避开分数可比性问题。
对于文档d,其RFFF总分为所有参与融合的检索系统中的得分加权和:
$$
RRF(d) = Σ [ wᵢ / (k + rankᵢ(d)) ]
$$
- wᵢ:第 i 个检索系统的权重(默认 = 1,平等权重)
- k:平滑参数(经验值默认 = 60,控制排名衰减速度)
- rankᵢ(d):文档 d 在第 i 个检索系统中的排名(通常 1-indexed,未出现则视为无穷大)
现实世界中,有许多数据都是非结构化数据,要从非结构化的数据中检索信息,需要利用大模型的理解能力,将非结构化的数据翻译成针对特定数据源的结构化数据查询语言或带有过滤条件的请求,这个过程叫查询构建。
1、文本到元数据过滤器:构建向量索引时,常常会为文档块附加元数据,这些元数据能辅佐做语义搜索之外的精确过滤功能。如langchain中的SelfQueryRetriever自查询检索器。
- 接收输入:获取用户包含「语义需求」和「元数据过滤需求」的原始自然语言查询。
- LLM 解析:查询构造器调用LLM,结合预定义的元数据 Schema 和文档描述,生成两个结果 ——① 优化后的纯语义查询(保留核心语义,去除过滤条件);② 通用抽象结构化过滤条件(与向量库无关)。
- 格式翻译:结构化查询翻译器将抽象过滤条件,转为当前向量库(如 Chroma)支持的原生过滤语法。
- 双重检索:向量库先执行语义检索(匹配纯语义查询),再对结果做元数据精准过滤(匹配翻译后条件),得到双重符合要求的文档。
- 返回结果:将文档按相似度排序,格式化(含内容 + 元数据)后返回给用户。
from dotenv import load_dotenv
import os
from langchain_chroma import Chroma
from langchain_classic.chains.query_constructor.base import AttributeInfo
from langchain_classic.retrievers.self_query.base import SelfQueryRetriever
from langchain_community.chat_models import ChatTongyi
from langchain_core.documents import Document
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
load_dotenv()
dashscope_api_key="sk-XXX"
llm = ChatTongyi(
model="qwen-turbo",
api_key=dashscope_api_key
)
embeddings = DashScopeEmbeddings(dashscope_api_key=dashscope_api_key)
documents = [
Document(
page_content="大语言模型(LLM)的注意力机制详解,包括自注意力、交叉注意力的实现原理和优化技巧。",
metadata={
"doc_type": "技术文档",
"publish_year": 2024,
"author": "李四",
"domain": "人工智能"
}
),
Document(
page_content="Chroma向量数据库的本地部署与API使用指南,包含数据入库、检索、过滤的完整示例。",
metadata={
"doc_type": "操作手册",
"publish_year": 2023,
"author": "张三",
"domain": "大数据"
}
),
Document(
page_content="RAG系统搭建最佳实践,涵盖混合检索(BM25+向量检索)、RRF融合、精排优化。",
metadata={
"doc_type": "技术文档",
"publish_year": 2024,
"author": "张三",
"domain": "人工智能"
}
),
Document(
page_content="网络安全威胁检测方法,包括基于特征匹配和基于异常行为的两种核心方案。",
metadata={
"doc_type": "安全报告",
"publish_year": 2022,
"author": "王五",
"domain": "网络安全"
}
),
Document(
page_content="Sentence-BERT嵌入模型的微调教程,针对中文场景优化分词和语义表征能力。",
metadata={
"doc_type": "技术文档",
"publish_year": 2024,
"author": "李四",
"domain": "自然语言处理"
}
)
]
vector_db = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./chroma_self_query_demo" # 本地存储路径,可查看生成的文件
)
metadata_field_info = [
AttributeInfo(
name="doc_type",
description="文档的类型,可选值:技术文档、操作手册、安全报告",
type="string"
),
AttributeInfo(
name="publish_year",
description="文档的发布年份,是一个整数",
type="integer"
),
AttributeInfo(
name="author",
description="文档的作者姓名,是一个字符串",
type="string"
),
AttributeInfo(
name="domain",
description="文档所属的技术领域,可选值:人工智能、大数据、网络安全、自然语言处理",
type="string"
)
]
document_content_description = "各类技术领域的文档,涵盖人工智能、大数据、网络安全等方向"
self_query_retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vector_db,
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
verbose=True, # 开启详细日志,可查看LLM解析出的结构化查询条件
k=1 # 默认返回前3条匹配结果
)
query="查询2024年发布的文档,并且是张三发布的文档"
result=self_query_retriever.invoke(query)
for index,message in enumerate(result,1):
print(message.page_content)
print(message.metadata)
- 配置元数据字段 (
metadata_field_info) :通过AttributeInfo为每个元数据字段定义名称、类型和一份清晰的自然语言description,LLM依赖元数据理解和处理用户查询 - 创建自查询检索器 (
SelfQueryRetriever.from_llm) :from_llm方法在底层执行了两个核心操作:- 加载查询构造器:利用方法
load_query_constructor_runnable创建一个可查询的构造器,将用户的自然语言查询转换为一个通用的、结构化的查询对象。 - 获取内置翻译器:通过往
_get_builtin_translator方法中传入向量数据,自动匹配一个内置的翻译器。将上一步生成的通用查询对象,翻译成Chroma数据库能够原生理解和执行的过滤语法。
- 加载查询构造器:利用方法
def from_llm(
cls,
llm: BaseLanguageModel,
vectorstore: VectorStore,
document_contents: str,
metadata_field_info: Sequence[AttributeInfo | dict],
structured_query_translator: Visitor | None = None,
chain_kwargs: dict | None = None,
enable_limit: bool = False, # noqa: FBT001,FBT002
use_original_query: bool = False, # noqa: FBT001,FBT002
**kwargs: Any,
) -> "SelfQueryRetriever":
if structured_query_translator is None:
structured_query_translator = _get_builtin_translator(vectorstore)
chain_kwargs = chain_kwargs or {}
#提取「当前向量库支持的默认运算符列表」,自动补全到chain_kwargs中
if (
"allowed_comparators" not in chain_kwargs
and structured_query_translator.allowed_comparators is not None
):
chain_kwargs["allowed_comparators"] = (
structured_query_translator.allowed_comparators
)
if (
"allowed_operators" not in chain_kwargs
and structured_query_translator.allowed_operators is not None
):
chain_kwargs["allowed_operators"] = (
structured_query_translator.allowed_operators
)
query_constructor = load_query_constructor_runnable(
llm,
document_contents,
metadata_field_info,
enable_limit=enable_limit,
**chain_kwargs,
)
query_constructor = query_constructor.with_config(
run_name=QUERY_CONSTRUCTOR_RUN_NAME,
)
return cls(
query_constructor=query_constructor,
vectorstore=vectorstore,
use_original_query=use_original_query,
structured_query_translator=structured_query_translator,
**kwargs,
)除扁平化元数据,还支持Cypher图数据库,通过利用大语言模型将用户的自然语言问题直接翻译成一句精准的 Cypher 查询语句
from dotenv import load_dotenv
import os
from neo4j import GraphDatabase
from langchain_community.chat_models import ChatTongyi
from langchain_community.graphs import Neo4jGraph
from langchain_neo4j import GraphCypherQAChain
load_dotenv()
dashscope_api_key = os.getenv("DASHSCOPE_API_KEY")
neo4j_uri = os.getenv("NEO4J_URI")
neo4j_username = os.getenv("NEO4J_USERNAME")
neo4j_password = os.getenv("NEO4J_PASSWORD")
llm = ChatTongyi(
model="qwen-turbo",
api_key=dashscope_api_key
)
def init_cyber_graph():
# 连接Neo4j数据库
driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_username, neo4j_password))
# 定义Cypher语句:创建Cyber安全图谱(资产-漏洞-威胁)
cypher_commands = [
# 清空现有数据(测试用,避免重复创建)
"MATCH (n) DETACH DELETE n",
# 创建「资产」节点
"""
CREATE (web:Asset {name: "Web服务器", type: "应用服务器", ip: "192.168.1.100", status: "运行中"})
CREATE (db:Asset {name: "MySQL数据库", type: "数据库", ip: "192.168.1.101", status: "运行中"})
CREATE (fw:Asset {name: "防火墙", type: "网络设备", ip: "192.168.1.1", status: "运行中"})
""",
# 创建「漏洞」节点
"""
CREATE (log4j:Vulnerability {name: "Log4j2远程代码执行", cve: "CVE-2021-44228", severity: "高危", publish_date: "2021-12-10"})
CREATE (sql:Vulnerability {name: "SQL注入", cve: "CVE-2023-XXXX", severity: "中危", publish_date: "2023-05-20"})
CREATE (auth:Vulnerability {name: "弱口令认证", cve: "CVE-2022-YYYY", severity: "高危", publish_date: "2022-08-15"})
""",
# 创建「威胁」节点
"""
CREATE (ransom:Threat {name: "勒索软件", type: "恶意软件", damage: "严重", target: "企业核心资产"})
CREATE (phish:Threat {name: "钓鱼攻击", type: "社会工程学", damage: "中等", target: "员工账号"})
CREATE (hack:Threat {name: "黑客远程入侵", type: "网络攻击", damage: "极严重", target: "服务器资产"})
""",
# 创建节点之间的关联关系
"""
# 资产存在漏洞
MATCH (web:Asset {name: "Web服务器"}), (log4j:Vulnerability {name: "Log4j2远程代码执行"})
CREATE (web)-[:HAS_VULNERABILITY {discover_date: "2024-01-05"}]->(log4j)
MATCH (db:Asset {name: "MySQL数据库"}), (sql:Vulnerability {name: "SQL注入"})
CREATE (db)-[:HAS_VULNERABILITY {discover_date: "2024-02-10"}]->(sql)
MATCH (fw:Asset {name: "防火墙"}), (auth:Vulnerability {name: "弱口令认证"})
CREATE (fw)-[:HAS_VULNERABILITY {discover_date: "2024-03-15"}]->(auth)
# 漏洞可被威胁利用
MATCH (log4j:Vulnerability {name: "Log4j2远程代码执行"}), (hack:Threat {name: "黑客远程入侵"})
CREATE (log4j)-[:CAN_BE_EXPLOITED_BY {exploit_success_rate: "80%"}]->(hack)
MATCH (sql:Vulnerability {name: "SQL注入"}), (ransom:Threat {name: "勒索软件"})
CREATE (sql)-[:CAN_BE_EXPLOITED_BY {exploit_success_rate: "60%"}]->(ransom)
MATCH (auth:Vulnerability {name: "弱口令认证"}), (phish:Threat {name: "钓鱼攻击"})
CREATE (auth)-[:CAN_BE_EXPLOITED_BY {exploit_success_rate: "90%"}]->(phish)
"""
]
# 执行Cypher语句,构建图谱
with driver.session() as session:
for cmd in cypher_commands:
session.run(cmd)
driver.close()
def init_cyber_qa_chain():
# 连接Neo4j图数据库,自动加载图谱结构
graph = Neo4jGraph(
url=neo4j_uri,
username=neo4j_username,
password=neo4j_password
)
graph.refresh_schema()
print("\n📋 图谱结构详情:")
print(graph.get_schema())
qa_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True, # 开启详细日志,查看生成的Cypher语句
return_direct=False, # False:返回LLM整理后的自然语言答案;True:直接返回Cypher查询结果
cypher_prompt_kwargs={
"schema": graph.get_schema(), # 传入图谱结构,帮助LLM生成准确Cypher
"table_context": "Cyber安全图谱,包含资产、漏洞、威胁三类节点及关联关系"
}
)
return qa_chain
if __name__ == "__main__":
init_cyber_graph()
cyber_qa_chain = init_cyber_qa_chain()
print("\n=== 测试查询1:资产漏洞查询 ===")
query1 = "Web服务器存在什么漏洞?这个漏洞的CVE编号是什么?"
result1 = cyber_qa_chain.invoke({"query": query1})
print(f"📝 答案:{result1['result']}")查询优化
用户复杂、包含歧义的提问往往和文档存在偏差。用户在查询前有必要进行预处理,包含查询翻译与查询路由两项关键的查询重构。
查询翻译的方法:
- 提示工程:通过
prompt引导 LLM 将用户的原始查询改写得更清晰、更具体,或者对原数据进行一定的排列后再输出。 - 多查询分解:将一个复杂的问题拆分成多个更简单、更具体的子问题,然后分别对每个子问题进行检索,最后将所有检索到的结果合并、去重,形成一个更全面的上下文。
- 退步提示:引导 LLM 从用户的原始具体问题中,生成一个更高层次、更概括的
退步问题,这个退步问题旨在探寻原始问题背后的通用原理或核心概念。将通用原理作为上下文,再结合原始的具体问题,进行推理并生成最终答案。 - 假设性嵌入:先利用一个生成式大语言模型(LLM)来生成一个
假设性的、能够完美回答该查询的文档,将这个内容详实的假设性文档进行向量化,用其生成的向量去数据库中寻找与之最相似的真实文档。
查询路由:
- 基于LLM意图识别:当系统具备多种处理能力,需要
LLM先进行意图识别,根据意图识别的结果动态选择最合适的检索器或工具。 - 嵌入相似性路由:为每个路由创建一个详细的文本描述,并使用嵌入模型将其转换为向量。通过
map将路由名称和链连起来。后续在发起查询的时候,从模型向量找到相似度最高的路由,再调用路由。
重排
在检索增强生成RAG、信息检索IR流程中,标准链路为:多路召回 → 粗排(初排)→ 重排,重排是RAG系统里用高精度模型对小批量候选做二次精排序的环节,核心是修正召回的粗匹配错误:
1、Cross-Encoder 重排:基于 BERT/RoBERTa 等双塔全交互编码器的重排模型
- 前置步骤:上游召回 / 粗排产出 Top-K 候选文档(一般 K=50~200,受限于速度)。
- 输入构造:对每个候选文档 doc,与查询 query拼接为单一序列(通用格式:
[CLS] query [SEP] doc [SEP]) - 全交互编码:将拼接序列送入 Cross-Encoder,模型内部做 query 与 doc 所有 token 之间的全局自注意力,完成完整语义交互。
- 相关性打分:取 或对应层的表征,通过线性层映射为 0~1 相关性分数(点 wise 回归 / 二分类)。
- 重排:所有候选文档按分数降序排列,输出最终结果。
2、ColBERT重排:
- 离线预处理:用 ColBERT 的文档编码器,将语料中所有文档编码为 词级别嵌入矩阵
$$
Embsdoc∈RLdoc×D(保留每个 token 的细粒度向量,而非单个句向量)。
$$
- 在线查询编码:用 ColBERT 的查询编码器,将 query 编码为词级别嵌入矩阵
$$
Embsquery∈RLq×D
$$
- 延迟交互打分:
-
计算 query 每个 token 嵌入 与 doc 每个 token 嵌入的余弦相似度;
-
对 query 每一个 token,取 doc 侧的最大相似度(MaxSim);
-
对所有 MaxSim 值求和,得到文档总相关性分数:
$$
Score(q,d)=∑t∈qmaxt′∈dcosine(Embq(t),Embd(t′))
$$
3、RankLLM重排:以通用大语言模型(LLM)为打分 / 排序器的重排方案
- 上游得到 Top-K 候选文档;
- 构造面向 LLM 的 Prompt,将
query+ 候选文档文本输入 LLM; - LLM 输出分数 / 排序关系;
- 解析结果,对候选集重排。
压缩
这里的压缩指的是对召回 / 重排后的文档文本做内容精简,只保留和 Query 语义相关的片段,剔除无关、冗余、噪声内容,使信息密度提高,LLM聚焦于关键依据。主流的压缩方案一般有:
截断压缩:
- 取重排后的 Top-N 文档
- 按规则截断:头部截断、尾部截断、中间滑动窗口取固定长度
字面匹配压缩:
- 对 Query 做关键词提取(TF-IDF、分词、停用词过滤)
- 遍历文档,抽取包含最多 Query 关键词的连续句子 / 段落
- 按顺序拼接片段,作为压缩结果
抽取式语义压缩:
- 把每篇文档拆成细粒度单元:句子、短 chunk(32~128token)
- 对每个小块,用模型计算
(Query, 小块)的相关性分数 - 按分数筛选 Top-K 小块,按原文顺序拼接
生成式压缩:
- 输入:
Query + 完整文档 - Prompt LLM:
只保留和Query直接相关的内容,用简洁原文复述,删除无关 - LLM 输出一段精简、通顺、只含相关信息的文本
端到端上下文压缩器
以 LangChain ContextualCompressionRetriever实现上下文压缩,使用一个指定的 DocumentCompressor 对这些文档进行处理,封装流程:
- 基础检索器召回文档
- 压缩器(可绑定
CrossEncoder/ColBERT/LLM)接收 Query+Docs, - 自动做片段打分 + 筛选 + 拼接
- 直接输出压缩后的文档列表,接入
LLM
在langchain中内置了多种DocumentCompressor
import os
from langchain_community.chat_models import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_community.vectorstores import Chroma
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_classic.retrievers.document_compressors import EmbeddingsFilter
from langchain_classic.retrievers.document_compressors import LLMChainFilter
dashscope_api_key="sk-XXX"
llm = ChatTongyi(
model="qwen-turbo",
api_key=dashscope_api_key
)
# 通用嵌入模型(用于FAISS向量库、EmbeddingsFilter)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=dashscope_api_key
)
# embeddings = HuggingFaceEmbeddings(
# model_name="BAAI/bge-small-zh-v1.5",
# model_kwargs={'device': device}
# )
# 3. 准备测试文档(包含冗余内容,体现压缩效果)
documents = [
Document(
page_content="""
RAG系统搭建指南(2024版)
【环境准备】(冗余内容)
操作系统:Ubuntu 22.04
Python版本:3.10+
所需依赖:langchain、chroma、faiss-cpu
【核心步骤】(核心内容)
1. 文档加载与分割:使用RecursiveCharacterTextSplitter分割文档,chunk_size设为500。
2. 向量入库:将分割后的文档通过Embeddings模型向量化,存入FAISS或Chroma。
3. 检索配置:使用混合检索(BM25+向量检索),提升召回率。
4. 结果融合:使用RRF算法融合两种检索结果,避免单一检索的局限性。
【部署注意】(冗余内容)
部署方式:Docker容器化部署
端口配置:映射8080端口对外提供服务
""",
metadata={"title": "RAG系统搭建指南", "type": "技术文档"}
),
Document(
page_content="""
Sentence-BERT微调教程(中文场景)
【硬件要求】(冗余内容)
GPU:NVIDIA A10 24G
内存:32G DDR4
【微调步骤】(核心内容)
1. 数据集准备:使用中文语义匹配数据集(如LCQMC),格式为jsonl。
2. 模型加载:加载预训练模型sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2。
3. 训练配置:学习率设为2e-5,训练轮数设为5,batch_size设为32。
4. 效果评估:使用余弦相似度评估微调后模型的语义表征能力,目标相似度≥0.85。
【保存与发布】(冗余内容)
保存格式:pytorch_model.bin
发布平台:Hugging Face Hub
""",
metadata={"title": "Sentence-BERT微调教程", "type": "技术文档"}
),
Document(
page_content="""
办公室网络使用规范(无关文档,用于测试过滤效果)
1. 禁止使用办公网络访问非法网站。
2. 禁止在办公网络中传输涉密文件。
3. 办公设备需定期查杀病毒,每周至少1次。
""",
metadata={"title": "办公室网络使用规范", "type": "行政文档"}
)
]
faiss_db = Chroma.from_documents(documents, embeddings)
base_retriever = faiss_db.as_retriever(search_kwargs={"k": 1})
compressor=LLMChainExtractor.from_llm(llm)
compression_retriever=ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
query = "RAG系统搭建的核心步骤有哪些?"
base_results=base_retriever.invoke(query)
for i, doc in enumerate(base_results, 1):
print(f"\n{i}. 文档标题:{doc.metadata['title']}")
print(f"内容长度:{len(doc.page_content)} 字符")
print(f"内容预览:{doc.page_content}")
compressed_results = compression_retriever.invoke(query)
for i, doc in enumerate(compressed_results, 1):
print(f"\n{i}. 文档标题:{doc.metadata['title']}")
print(f"内容长度:{len(doc.page_content)} 字符")
print(f"核心内容:\n{doc.page_content}")\
# compressor = EmbeddingsFilter(
# embeddings=embeddings,
# similarity_threshold=0.5
# )
#
# compression_retriever = ContextualCompressionRetriever(
# base_compressor=compressor,
# base_retriever=base_retriever
# )
#
# query = "RAG系统搭建的核心步骤有哪些?"
# base_results = base_retriever.invoke(query)
# for i, doc in enumerate(base_results, 1):
# print(f"\n{i}. 文档标题:{doc.metadata['title']}")
# print(f"文档类型:{doc.metadata['type']}")
#
# print("挑选后的文档")
# compressed_results = compression_retriever.invoke(query)
# for i, doc in enumerate(compressed_results, 1):
# print(f"\n{i}. 文档标题:{doc.metadata['title']}")
# print(f"文档内容预览:\n{doc.page_content}")
# compressor = LLMChainFilter.from_llm(llm)
#
# compression_retriever = ContextualCompressionRetriever(
# base_compressor=compressor,
# base_retriever=base_retriever
# )
#
# query = "RAG系统搭建的核心步骤有哪些?"
# print("【基础检索结果(含无关文档)】")
# base_results = base_retriever.invoke(query)
# for i, doc in enumerate(base_results, 1):
# print(f"\n{i}. 文档标题:{doc.metadata['title']}")
# print(f"文档类型:{doc.metadata['type']}")
#
# print("\n【压缩后结果(仅保留相关文档)】")
# compressed_results = compression_retriever.invoke(query)
# for i, doc in enumerate(compressed_results, 1):
# print(f"\n{i}. 文档标题:{doc.metadata['title']}")
# print(f"文档完整内容(无片段提取,仅过滤无关文档):\n{doc.page_content}...")| 压缩器类型 | 核心逻辑 | 速度 | 成本 | 适用场景 |
|---|---|---|---|---|
| LLMChainExtractor | 提取文档内相关片段,丢弃冗余 | 慢 | 高(LLM 调用,提炼片段) | 文档冗余多,需要精准核心片段 |
| LLMChainFilter | 判断文档整体相关性,保留 / 丢弃整个文档 | 中 | 中(LLM 调用,仅判断) | 需快速过滤完全无关文档,核心文档冗余少 |
| EmbeddingsFilter | 向量相似度匹配,过滤低于阈值的文档 | 快 | 低(无 LLM 调用,仅向量计算) | 大规模文档预过滤,降低后续处理压力 |
参考链接:https://datawhalechina.github.io/all-in-rag/#/chapter2/04_data_load

文章标题:RAG学习
文章链接:https://www.aiwin.net.cn/index.php/archives/4529/
最后编辑:2026 年 2 月 6 日 16:03 By Aiwin
许可协议: 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)